

Prometheus是一个流行的开源监控解决方案,用于记录和查询系统的指标数据。它提供了多种方式来监控目标的状态、警报并进行查询分析。
安装前准备
安装前先完成NetBird组网,如果你不想把监控指标端口暴露在公网上的话。 请安装好docker和docker-compose,如何安装见官方文档。
NODE客户端安装
docker-compose.yml
node_exporter:
image: quay.io/prometheus/node-exporter:latest
container_name: node_exporter
command:
- '--path.rootfs=/host'
network_mode: host
pid: host
restart: unless-stopped
volumes:
- '/:/host:ro,rslave'启动
docker-compose up -d
#确认安装是否成功,如果输出一大堆指标数据说明成功
curl localhost:9100/metrics服务端安装
密码生成器
apt install apache2-utils
htpasswd -nBC 12 '' | tr -d ':\n'
#输入密码和确认密码,并将得到的加密后的密码牢记docker-compose.yml
prometheus:
container_name: prometheus
image: prom/prometheus:latest
volumes:
- /data/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- /data/prometheus/htpasswd.yml:/etc/prometheus/htpasswd.yml
- /data/prometheus/alert/:/etc/prometheus/alert/
- /data/prometheus/data/:/prometheus
ports:
- '9090:9090'
restart: always
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.config.file=/etc/prometheus/htpasswd.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
- '--storage.tsdb.retention=30d'
- '--web.enable-admin-api'
- '--web.enable-lifecycle'
- '--web.external-url=https://prometheus.xxx.com/'
alertmanager:
container_name: alertmanager
image: prom/alertmanager:latest
volumes:
- /data/alertmanager/:/alertmanager/
- /data/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
- /data/prometheus/htpasswd.yml:/etc/alertmanager/htpasswd.yml
ports:
- '9093:9093'
restart: always
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--storage.path=/alertmanager'
- '--web.config.file=/etc/alertmanager/htpasswd.yml'
- '--web.external-url=https://alertmanager.xxx.com/'
grafana:
container_name: grafana
image: grafana/grafana:latest
volumes:
- /data/grafana:/var/lib/grafana
ports:
- '3000:3000'
restart: always参数说明 --storage.tsdb.retention=30d 数据保留30天 --web.enable-admin-api 控制对admin HTTP API的访问,其中包括删除时间序列等功能 例子:curl -X POST -g 'http://localhost:9090/api/v1/admin/tsdb/delete_series?match[]={instance="xxx.xxx.xxx.xxx:9100"}' --web.enable-lifecycle 支持热更新 例子:curl -X POST localhost:9090/-/reload 注意:在容器外修改yaml配置文件是徒劳的,因为容器外修改文件容器内是不会生效的,具体原因就不讲了,感兴趣的同学可以自行搜索了解。所以在容器外修改配置文件只能restart容器。
创建挂载目录
cd /data
mkdir prometheus alertmanager grafana
chmod a+rw grafana/ alertmanager/
cd /data/prometheus/
mkdir data
chmod a+rw data/prometheus配置
密码文件路径:/data/prometheus/htpasswd.yml,内容如下
basic_auth_users:
用户名: 之前生成的加密密码配置文件路径:/data/prometheus/prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
alerting:
alertmanagers:
- static_configs:
- targets:
- 服务端IP:9093
basic_auth:
username: 用户名
password: 明文密码
rule_files:
- "alert/*rules.yml"
scrape_configs:
- job_name: 'prometheus'
basic_auth:
username: 用户名
password: 明文密码
static_configs:
- targets: ['服务端IP:9090']
- job_name: 'node'
static_configs:
- targets: ['客户端IP:9100']
labels:
name: '机器名'
vendor: '鸡场名称'
group: '分类,比如国家'
- targets: ['其他节点客户端IP:9100']
labels:
name: '机器名'
vendor: '鸡场名称'
group: '分类'
- job_name: 'alertmanager'
basic_auth:
username: 用户名
password: 明文密码
static_configs:
- targets: ['服务端IP:9093']IP查看方式:
netbird statusNODE鸡告警规则配置
配置文件路径:/data/prometheus/alert/alert-node-rules.yml
groups:
- name: node_usage_record_rules
interval: 1m
rules:
- record: cpu:usage:rate1m
expr: (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[3m])) by (instance,vendor,account,group,name)) * 100
- record: mem:usage:rate1m
expr: (1 - node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100
- name: node-alert
rules:
- alert: NodeDown
expr: up{job="node"} == 0
for: 5m
labels:
severity: critical
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} down"
description: "Instance: {{ $labels.instance }} 已经宕机 5分钟"
value: "{{ $value }}"
- alert: NodeCpuHigh
expr: (1-sum(increase(node_cpu_seconds_total{job="node",mode="idle"} [5m]) ) by(instance) / sum(increase(node_cpu_seconds_total{job="node"} [5m]) ) by(instance) )*100 > 80
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} cpu使用率过高"
description: "CPU 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeCpuIowaitHigh
expr: avg by (instance) (rate(node_cpu_seconds_total{job="node",mode="iowait"}[5m])) * 100 > 50
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} cpu iowait 使用率过高"
description: "CPU iowait 使用率超过 50%"
value: "{{ $value }}"
- alert: NodeLoad5High
expr: node_load5 > (count by (instance) (node_cpu_seconds_total{job="node",mode='system'})) * 1.2
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} load(5m) 过高"
description: "Load(5m) 过高,超出cpu核数 1.2倍"
value: "{{ $value }}"
- alert: NodeMemoryHigh
expr: (1 - node_memory_MemAvailable_bytes{job="node"} / node_memory_MemTotal_bytes{job="node"}) * 100 > 90
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} memory 使用率过高"
description: "Memory 使用率超过 90%"
value: "{{ $value }}"
- alert: NodeDiskRootHigh
expr: (1 - node_filesystem_avail_bytes{job="node",fstype=~"ext.*|xfs"} / node_filesystem_size_bytes{job="node",fstype=~"ext.*|xfs"}) * 100 > 90
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk 分区使用率过高"
description: "Disk 分区使用率超过 90%"
value: "{{ $value }}"
- alert: NodeDiskBootHigh
expr: (1 - node_filesystem_avail_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/boot"} / node_filesystem_size_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/boot"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/boot 分区) 使用率过高"
description: "Disk(/boot 分区) 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeDiskReadHigh
expr: irate(node_disk_read_bytes_total{job="node"}[5m]) > 20 * (1024 ^ 2)
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk 读取字节数 速率过高"
description: "Disk 读取字节数 速率超过 20 MB/s"
value: "{{ $value }}"
- alert: NodeDiskWriteHigh
expr: irate(node_disk_written_bytes_total{job="node"}[5m]) > 20 * (1024 ^ 2)
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk 写入字节数 速率过高"
description: "Disk 写入字节数 速率超过 20 MB/s"
value: "{{ $value }}"
- alert: NodeDiskReadRateCountHigh
expr: irate(node_disk_reads_completed_total{job="node"}[5m]) > 3000
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk iops 每秒读取速率过高"
description: "Disk iops 每秒读取速率超过 3000 iops"
value: "{{ $value }}"
- alert: NodeDiskWriteRateCountHigh
expr: irate(node_disk_writes_completed_total{job="node"}[5m]) > 3000
for: 5m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk iops 每秒写入速率过高"
description: "Disk iops 每秒写入速率超过 3000 iops"
value: "{{ $value }}"
- alert: NodeFilefdAllocatedPercentHigh
expr: node_filefd_allocated{job="node"} / node_filefd_maximum{job="node"} * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} filefd 打开百分比过高"
description: "Filefd 打开百分比 超过 80%"
value: "{{ $value }}"
- alert: NodeNetworkNetinBitRateHigh
expr: avg by (instance) (irate(node_network_receive_bytes_total{device=~"eth0|docker0|wt0"}[1m]) * 8) > 20 * (1024 ^ 2) * 8
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} network 接收比特数 速率过高"
description: "Network 接收比特数 速率超过 20MB/s"
value: "{{ $value }}"
- alert: NodeNetworkNetoutBitRateHigh
expr: avg by (instance) (irate(node_network_transmit_bytes_total{device=~"eth0|docker0|wt0"}[1m]) * 8) > 20 * (1024 ^ 2) * 8
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} network 发送比特数 速率过高"
description: "Network 发送比特数 速率超过 20MB/s"
value: "{{ $value }}"
- alert: NodeNetworkNetinPacketErrorRateHigh
expr: avg by (instance) (irate(node_network_receive_errs_total{device=~"eth0|docker0|wt0"}[1m])) > 15
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 接收错误包 速率过高"
description: "Network 接收错误包 速率超过 15个/秒"
value: "{{ $value }}"
- alert: NodeProcessBlockedHigh
expr: node_procs_blocked{job="node"} > 10
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 当前被阻塞的任务的数量过多"
description: "Process 当前被阻塞的任务的数量超过 10个"
value: "{{ $value }}"
- alert: NodeTimeOffsetHigh
expr: abs(node_timex_offset_seconds{job="node"}) > 3 * 60
for: 2m
labels:
severity: info
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 时间偏差过大"
description: "Time 节点的时间偏差超过 3m"
value: "{{ $value }}"
相关的监控规则可参考:https://samber.github.io/awesome-prometheus-alerts/
alertmanager配置
配置文件路径:/data/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465' #邮箱smtp服务器代理,启用SSL发信, 端口一般是465
smtp_from: 'xxx@qq.com' #发送邮箱名称
smtp_auth_username: 'xxx@qq.com' #邮箱名称
smtp_auth_password: 'xxxxxxxxxx' #邮箱密码或授权码
smtp_require_tls: false
route:
receiver: 'default'
group_wait: 10s
group_interval: 1m
repeat_interval: 1h
group_by: ['alertname']
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname']
receivers:
- name: 'default'
email_configs:
- to: 'xxx@qq.com'
send_resolved: true
webhook_configs:
- url: 'http://IP:端口/robot/send'
send_resolved: true启动
docker-compose up -d
#查看日志是否有报错,未见报错信息说明启动成功
docker logs -f grafana
docker logs -f prometheus
docker logs -f alertmanagernginx配置
server {
listen 443 ssl;
server_name prometheus.xxx.com;
ssl_certificate /etc/nginx/cert/xxx.com.pem;
ssl_certificate_key /etc/nginx/cert/xxx.com.key;
access_log logs/prometheus.access.log main;
error_log logs/prometheus.error.log notice;
ssl_session_timeout 1d;
ssl_session_cache shared:MozSSL:10m;
ssl_session_tickets off;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers off;
location / {
proxy_set_header Host $host;
proxy_pass http://服务端IP:9090/;
}
}
server {
listen 443 ssl;
server_name grafana.xxx.com;
ssl_certificate /etc/nginx/cert/xxx.com.pem;
ssl_certificate_key /etc/nginx/cert/xxx.com.key;
access_log logs/grafana.access.log main;
error_log logs/grafana.error.log notice;
ssl_session_timeout 1d;
ssl_session_cache shared:MozSSL:10m;
ssl_session_tickets off;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers off;
location / {
add_header 'Access-Control-Allow-Origin' '*';
proxy_pass http://服务端IP:3000/;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
proxy_set_header Host $http_host;
proxy_http_version 1.1;
}
}
server {
listen 443 ssl;
server_name alertmanager.xxx.com;
ssl_certificate /etc/nginx/cert/xxx.com.pem;
ssl_certificate_key /etc/nginx/cert/xxx.com.key;
access_log logs/alertmanager.access.log main;
error_log logs/alertmanager.error.log notice;
ssl_session_timeout 1d;
ssl_session_cache shared:MozSSL:10m;
ssl_session_tickets off;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers off;
location / {
proxy_set_header Host $host;
proxy_pass http://服务端IP:9093/;
}
}重启nginx后接入cf 
初始化grafana
在浏览器访问https://grafana.xxx.com 在登录框输入用户名密码:admin/admin 登录后完成密码修改 完成后进入系统,点击右上角头像,选择Profile,完成用户名、名称、邮箱修改,下次你就可以用修改后的用户名或邮箱登录了。 
查看prometheus
新建浏览器窗口访问:https://prometheus.xxx.com/ 输入prometheus.yml配置文件中的用户名密码,进入系统。 点击菜单栏的Status,选择Targets  在界面看到UP表示健康指标正常采集,DOWN表示客户端连接失败
在界面看到UP表示健康指标正常采集,DOWN表示客户端连接失败 
配置grafana
配置数据源
回到grafana 点击左上角菜单图标,选择Add new connection  在搜索栏中输入prom,选择prometheus
在搜索栏中输入prom,选择prometheus  输入以下内容,prometheus的IP端口,开启认证,prometheus配置的用户名密码。
输入以下内容,prometheus的IP端口,开启认证,prometheus配置的用户名密码。  然后拉倒页面最底下,点击Save & Test,提示“Successfully queried the Prometheus API.”说明完成。
然后拉倒页面最底下,点击Save & Test,提示“Successfully queried the Prometheus API.”说明完成。
导入node监控面板
点击左上角菜单图标,选择Dashboards  在搜索框右侧点击NEW,选择Import
在搜索框右侧点击NEW,选择Import 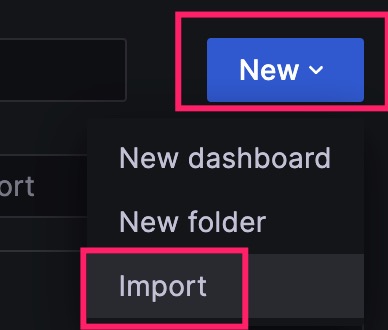 输入模版编号8919,点击Load
输入模版编号8919,点击Load  8919模版介绍 点击导入,由于我这边模板已经存在,被提示覆盖导入
8919模版介绍 点击导入,由于我这边模板已经存在,被提示覆盖导入  返回Dashboards,点击新导入的面板名称
返回Dashboards,点击新导入的面板名称  你就可以看到漂亮的监控页面啦!
你就可以看到漂亮的监控页面啦!
其他实例监控
prometheus非常强大,除了监控你的鸡群,还可以监控redis,mysql等等,这里是java监控的一个例子。
即时通讯告警接入
基于Bark,请根据这篇文档部署。 prometheus-webhook-bark 源码链接: https://pan.baidu.com/s/1OxCFdtyOGTFGJCBALl8ByA 提取码: 14n9 如果你懂JAVA开发,请下载prometheus-webhook-bark.tar.gz编译 如果你懂JAVA运行环境部署,请下载prometheus-webhook-bark.jar自行部署 如果你只会docker,请下载prometheus-webhook-bark.latest.tar部署 以下是docker的部署方式: 加载镜像
docker load < prometheus-webhook-bark.latest.tar
docker-compose
prometheus-webhook-bark:
image: prometheus-webhook-bark:latest
container_name: prometheus-webhook-bark
restart: always
volumes:
- /data/app/prometheus-webhook-bark/:/opt/resources/
ports:
- '8084:8084'
配置文件路径 /data/app/prometheus-webhook-bark/application.properties
server.port=8084
spring.application.name=prometheuswebhookbark
bark.dk=xxx 修改成你的bark key
bark.openapi=https://bark.xxx.com/push 修改成你的bark域名
启动后,请手工关闭一只鸡的node客户端,如果部署无问题的话,你的iphone手机、邮箱5分钟后将收到告警信息【设置了延迟5分钟】  同时,你的prometheus和alertmanager界面上可看到告警信息
同时,你的prometheus和alertmanager界面上可看到告警信息 
 如果你4小时内不去修复,还会继续收到告警信息,如果你修复了故障,将收到恢复的信息。
如果你4小时内不去修复,还会继续收到告警信息,如果你修复了故障,将收到恢复的信息。

评论